WRDB Import lets you "map" the column or field names in your import file or table to standard WRDB field names (or PCodes or keywords). Consider the following situation: suppose you were given a comma-separated file of datasonde DO readings to import into WRDB containing three columns: "Date Collected", "Observed Value", "Battery Level". Field mapping allows you to correctly map these columns to WRDB fields so that the data are correctly interpreted. By simply clicking on the column headings, you can map these columns to "Date", "DO", and "Ignore" (i.e., we don't want to import the third column).
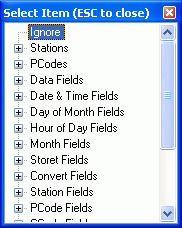
The field mapping in WRDB is very powerful (and perhaps a bit complex). To do the mapping, you must click on the hyperlinks in the PCode/Field row of the Column Field Names... grid on the preview form to display the field mapping list:
This list is divided into categories; expand the category and click on the desired item to map that column to that item. WRDB tries to help you out by examining the column headings and automatically assigning likely field names. In our example, if the first column ("Date Collected") had been given a more common name ("Date"), it would have been automatically assigned. However, because WRDB isn't sure about "Date Collected", it assigns the "Ignore" keyword instead, meaning "ignore this column entirely". All unrecognized column names are assigned "Ignore".
To assign the correct field, in the first column, click the "Ignore" keyword to show the mapping list, expand the "Date & Time Fields" group, and click the "Date" item. This maps "Date Collected" to "Date". Similarly, in the second column, click the "Ignore" keyword to show the mapping list, then expand the PCodes group, and select "DO" from the list (assuming that "DO" is a valid PCode in your PCodes Support table, of course). Leave the third column alone (we do want to ignore it).
All import files must specify at least the following four items: Station ID, Date_Time, PCode, and Result. We have the last three (if not specified, times will be set to 00:00; the PCode was set to "DO", and the Result values are the numbers imported.) That leaves the Station ID unassigned. You would do this by typing or selecting a Station ID in the "Title and Default Values" grid on the form. If you fail to provide enough information, you will get an error message.
Here are details on each group and item in the field mapping list:
|
Category |
Item |
Description |
|
Ignore |
All data in this column is ignored (not imported) |
|
|
Stations |
This list is dynamically created and consists of all Station IDs found in the Stations Support table for this project |
|
|
PCodes |
This list is dynamically created and consists of all parameter codes found in the PCodes Support table for this project |
|
|
Data Fields |
These are the standard field names in Working and Master tables; imported values are assigned directly to these fields without conversion. When indicated as "required field", remember that for all except Result, global values may be provided on the Preview form. |
|
|
Station identifier (required field) |
||
|
Date and time value (if time is omitted, defaults to 00:00) (required field) |
||
|
Parameter code (required field) |
||
|
Percent from left edge of water (actually is real number representing lateral position of reading in a cross section) (defaults to empty) |
||
|
Depth in meters (actually is real number representing depth of sample; may be any units) (defaults to empty) |
||
|
Compositing code (up to three character code) (defaults to empty) |
||
|
Result code (one character code used to characterize the result value--e.g., is it less than detection limit) (default to empty) |
||
|
Numeric value corresponding to the observed value or lab test result (required field) |
||
|
0 or 1 value indicating whether the value has been validated (defaults to 0; usually omit this and use WRDB features to assign it) |
||
|
Integer value indicating the batch ID of the data when transferred to the Master table (defaults to empty; usually omit this and use WRDB features to assign it) |
||
|
Date & Time Fields |
This group contains date and time keywords, as well as some special purpose entries and conversions |
|
|
Date_Time |
Date and time value (see below for formatting; must be space between date and time) |
|
|
Date |
Date only (allows / and - as separators, as well as MMDDYY, MDDYY, MMDDYYYY, MDDYYYY) |
|
|
Time |
Time only (HH:MM, H:MM, HHMM, HHMM, numeric value as portion of day (e.g., 0.25=06:00), --- or blank is 00:00) |
|
|
Time_DST |
Time only, assume collected using daylight saving time (will be converted to Standard time upon import) |
|
|
Julian |
Elapsed number of days (as real number) within a given year (will be prompted to specify year) |
|
|
Date_Time_Comb |
Combined date and time (same as Date_Time) |
|
|
Date_YMD |
Format for date must be exactly YYYYMMDD (8 characters) |
|
|
Year |
Year of observation (two or four digit) |
|
|
Month |
Month of year (1-12) |
|
|
Day |
Day of month (1-31) |
|
|
Hour |
Hour of day (0-24) |
|
|
Minute |
Minute of hour (0-60) |
|
|
Day of Month Fields |
Special keyword used to identify day of month for entire column--usually used when rows are hour of day and columns are days of month; cells contain observations |
|
|
Day 1 |
Day of month and year specified which are specified in header; time of observation can also be specified there |
|
|
... |
||
|
Day 31 |
||
|
Hour of Day Fields |
Special keyword used to identify hour of day for entire column--usually used when rows are dates and columns are hours of day; cells contain observations |
|
|
Hour 1 |
Hour of day for specified date associated with column (or specified in header) |
|
|
... |
||
|
Hour 24 |
||
|
Month Fields |
Special keyword used to identify month for entire column--usually used when rows are day of the month |
|
|
Jan |
Month associated with column |
|
|
... |
||
|
Dec |
||
|
STORET Fields |
These keywords are helpful when importing data from STORET |
|
|
PCode_Storet |
This forces all numeric PCodes to be left padded to five characters (e.g., 300 for DO becomes "00300") |
|
|
RCode_Storet |
Converts result codes used by STORET into those typically used by WRDB as follows:
K = < (all others are set to empty RCodes) |
|
|
Station_ID_Storet |
Because Stations IDs are not necessarily unique (due to multiple agencies) this creates new unique Station ID by appending the agency code; e.g., 0123456 becomes 0123456+12WRD |
|
|
Agency_Storet |
This identifies the column to use for the Station_ID_Storet conversion |
|
|
Units_Storet |
Converts standard unit codes used by STORET to those typically used by WRDB: A;B;C;D;E;F;G;H;I;J;K;L;M;N;O;P;Q;R;S;T;U;V;W;X;Y;Z; each get mapped to "mg/L", "ug/L", "mg/kg,ug/g", "ug/kg", "#/100ml", "#/ml", "#/L", "deg C", "distance", "deg F", "cfs", "gpm,gpd,mgd", "pc/L", "MPN", "percent", "no units", "time", "mmHg", "pH", "pc/gm", "#/sqft", "lb/day,lb/yr", "lb/effort", "production", "wt meas.", "none" |
|
|
Convert Fields (NOTE: these fields are not longer used; instead use the Conversion Groups feature) |
These keywords allow on-the-fly conversions from one value to another. This is done by creating ?Convert.csv files (as indicated below) having two columns: the first is the value you wish to convert from, and the second is the value you wish to convert to. The conversion file must be found in the Support directory (for Paradox users), WRDB program directory (for server-type data providers) or database directory (for all other types). Any values in your import file not found in the first column of this file will be set to '?xxxxx' where xxxxx is the original value. |
|
|
PCode_Convert |
Requires PCodeConvert.csv in the appropriate directory. |
|
|
RCode_Convert |
Requires RCodeConvert.csv in the appropriate directory. |
|
|
Station_ID_Convert |
Requires StationConvert.csv in the appropriate directory. |
|
|
The following groups are used to identify Support table import fields. |
||
|
Click on hyperlinks for a pop-up describing each field. |
||
|
PCode Fields |
||
|
CCode Fields |
||
|
RCode Fields |
||
|
QCode Fields |
||
|
Station Group Fields |
||
|
PCode Group Fields |
||
|
Branch Fields |
||